The Data Developer's Trick: How to Normalize VIN API Responses for Cleaner Code & Smarter Apps
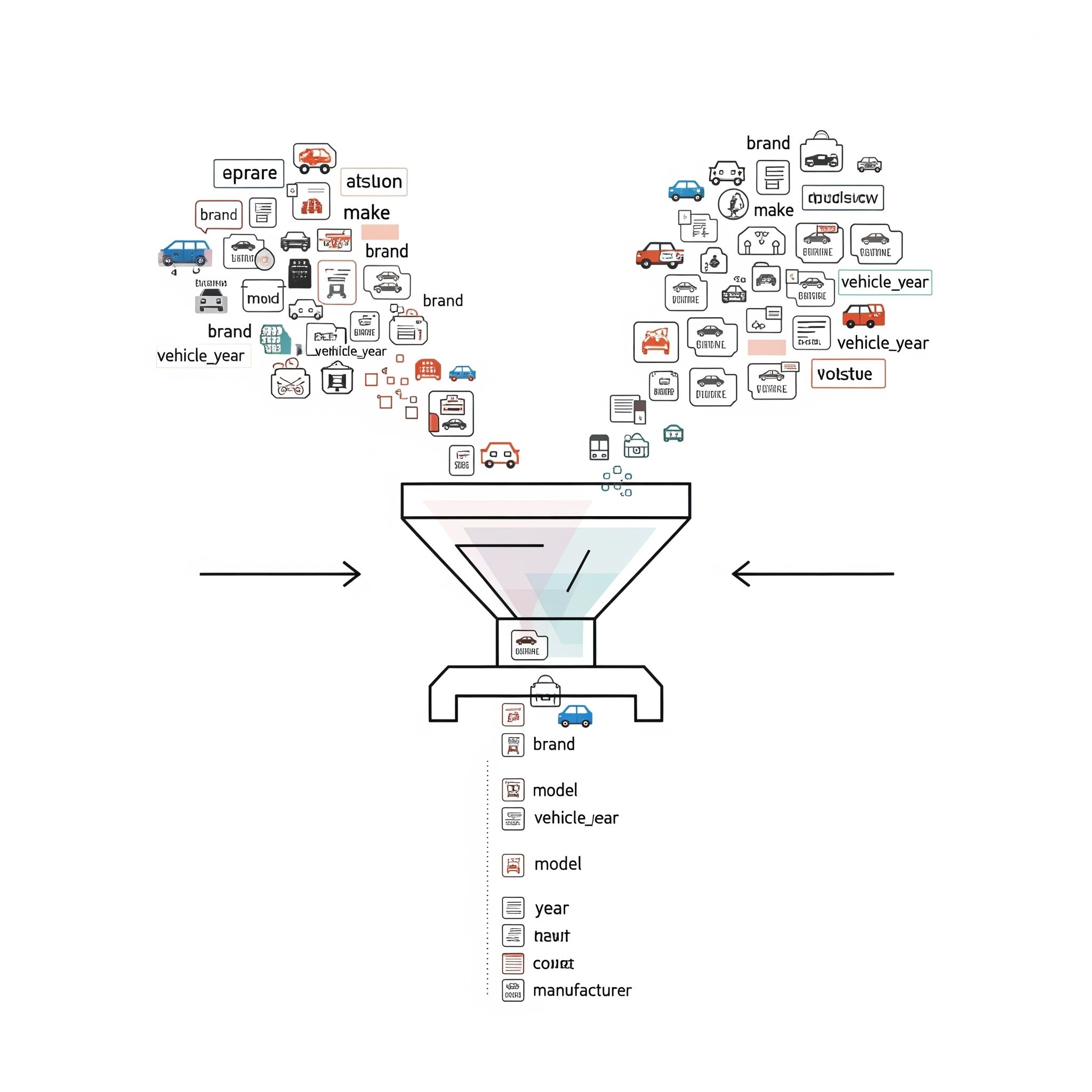
As a developer, you know the power of APIs. They are the building blocks of modern applications, allowing you to quickly integrate features like payments, maps, and, yes, vehicle data. But what happens when you're not getting all the data you need from a single source?
You might find yourself juggling responses from multiple APIs, each with its own unique data structure, field names, and formats. One API might return {"make": "Ford"}, while another gives you {"brand": "Ford"}. One uses vehicle_year for the year, and another uses just year.
This is where the developer's trick of data normalization comes in. It's a clean, elegant solution to a messy problem, and mastering it can save you countless hours of debugging and maintenance.
What is Data Normalization? (And Why You Need It)
In simple terms, data normalization is the process of restructuring data to a consistent, standardized format.
Imagine you're building a used car inventory application. You get vehicle data from three different APIs:
- API #1 (VIN Decoder): Returns a clean JSON response with fields like make, model, and engine_type.
- API #2 (History Report): Returns a different JSON with fields like vehicle_brand, model, and engine_spec.
- API #3 (Market Value): Returns data with fields named brand, model_name, and horsepower.
Without normalization, your code would be a tangle of if/else statements and conditional logic:
# A messy, non-normalized approach
if 'make' in api1_response:
make = api1_response['make']
elif 'vehicle_brand' in api2_response:
make = api2_response['vehicle_brand']
elif 'brand' in api3_response:
make = api3_response['brand']
else:
make = 'Unknown'This approach is fragile, hard to read, and difficult to maintain. Adding a new API means rewriting large parts of your codebase.
The "trick" is to create a single, internal data schema that all API responses are translated to.
The Normalization Process in Action
Let's walk through a practical example using Python. Our goal is to take inconsistent VIN data and convert it into a single, clean Vehicle object that our application can rely on.
Step 1: Define Your Target Schema Before you write any code, decide on the a standardized format your application will use. This is your "source of truth."
{
"vin": "VIN_NUMBER",
"make": "Vehicle Make",
"model": "Vehicle Model",
"year": "Vehicle Year",
"mileage": "Vehicle Mileage",
"condition": "Vehicle Condition"
}Tip: When designing your schema, use clear, descriptive field names (like make, not vehicle_brand) and consistent naming conventions (like snake_case).
Step 2: Create a Normalization Function This is where the magic happens. Your function will take a raw API response and map its messy fields to your clean schema.
def normalize_vin_data(api_response, api_source):
""" Normalizes a vehicle API response to a consistent schema. """
normalized_data = {
'vin': None,
'make': None,
'model': None,
'year': None,
'mileage': None,
'condition': None
}
if api_source == 'carsxe':
vehicle = api_response.get('vin', {})
normalized_data['vin'] = api_response.get('input', {}).get('vin')
normalized_data['make'] = vehicle.get('make')
normalized_data['model'] = vehicle.get('model')
normalized_data['year'] = vehicle.get('year')
# We'll use CarsXE's data as our primary source, as it's already well-structured.
elif api_source == 'api2':
# Example of handling a different, inconsistent API
normalized_data['vin'] = api_response.get('vin_number')
normalized_data['make'] = api_response.get('vehicle_brand')
normalized_data['model'] = api_response.get('model')
normalized_data['year'] = api_response.get('vehicle_year')
normalized_data['mileage'] = api_response.get('miles') # e.g., this API uses 'miles'
normalized_data['condition'] = api_response.get('vehicle_condition')
elif api_source == 'api3':
# Example of handling a third API with different fields
normalized_data['vin'] = api_response.get('vin_id')
normalized_data['make'] = api_response.get('brand')
normalized_data['model'] = api_response.get('model_name')
normalized_data['year'] = api_response.get('year_of_make')
# And so on for all relevant fields...
return normalized_data
Step 3: Use the Normalized Data in Your Application Now, regardless of which API you call, you can rely on a single, clean data object.
# Get data from two different hypothetical APIs
carsxe_data = carsxe.specs({"vin": "VIN_NUMBER"})
api2_data = fetch_from_api2("VIN_NUMBER")
# Normalize both responses
normalized_carsxe_vehicle = normalize_vin_data(carsxe_data, 'carsxe')
normalized_api2_vehicle = normalize_vin_data(api2_data, 'api2')
# Now your application code is clean and consistent!
# It doesn't matter which source the data came from.
print(f"Vehicle Make: {normalized_carsxe_vehicle['make']}")
print(f"Vehicle Make: {normalized_api2_vehicle['make']}")This is the core of the trick. Your business logic becomes simple because it only ever has to deal with your normalized data schema. Adding a new API is as easy as adding a new elif block to your normalization function.
Why This Trick Works (and Why CarsXE Helps)
This method is powerful because it decouples your application logic from external data sources. Your code becomes more resilient to API changes and easier to maintain.
At CarsXE, we understand the importance of clean, consistent data. That's why our API is built with a highly structured, logical JSON response from the get-go. Our goal is to be the single source of truth for your vehicle data, so you don't have to rely on multiple, inconsistent APIs.
With our comprehensive endpoints for VIN decoding, history, market value, and specs, you can often get all the data you need from one place, making the normalization process much simpler, or even unnecessary.
By embracing the trick of data normalization, you're not just writing cleaner code—you're building a more robust, scalable, and professional application. It's a simple hack that pays massive dividends in your development career.